Subgraph Layout in HyPL
In HyPL each relation is required to be associated with at least one population. When we depict HyPL CGMs graphically, we draw these populations in the style of plates, placing the variables inside. We can construct population sets that cannot be drawn; in this post I discuss how to represent them graphically to the end-user.
Our goal is to determine the layout of HyPL graphs. For now, we don't care about edges; we just want to lay out nodes/vertices so we can some clear visualization of the populations associated with different variables. This is challenging because there is a many-to-many relationship between populations and variables.
What we mean by "cannot be drawn"
Let's consider a CGM having two variables, and . is associated with populations foo and bar, while is associated with populations bar and baz. We draw the associated graph like so:
To recover the set of populations associated with each node, we simply union the labels on each container/plate/subgraph.
Two equivalent specifications
I want to highlight how I chose to specify this graph in the graph specification language I'm using (mermaid.js's flowchart syntax):
flowchart LR
subgraph pa [foo]
A("A")
end
subgraph pb [baz]
B("B")
end
subgraph pab [bar]
pa
pb
end
Note how in the final subgraph I declared that it contained the other subgraphs, i.e., those having labels pa and pb. I could just have easily had specified the graph like so:
flowchart LR
subgraph pab [bar]
subgraph pa [foo]
A("A")
end
subgraph pb [baz]
B("B")
end
end
In the latter case, the layout of the code matches the lexical scoping of the subgraphs and variables — that is, variable declarations for and are lexically inside the declarations of the subgraphs labeled pa and pb, and those subgraphs are lexically inside the declaration of pab. In the former case, I declared the smallest subgraphs for each variable (pa and pb) and then declared the containing subgraph pab using their references/labels.
Graphs with three variables
Let's add , which is associated with population ham. We draw this new graph like so:
|
Now, what happens when we associate also associate with foo? We can imagine a drawing that looks something like this:
|--------------------|
| bar |
| |-----| |------------------|
| | baz | | foo |-------|
| | | | | ham |
| | B | | A | |
| |-----| | | C |
|-------------|----------|-------|
So how would we express this in mermaid's flowchart syntax? Let's take a look at some possibilities:
| |
|
As you can see, neither of these images look like what we want. It stands to reason that mermaid doesn't natively support overlapping subgraphs.
The problem with what we want to depict is that pa needs to overlap with the boundary of pab, but each subgraph must be a strict subregion of exactly one immediately containing space. We violated that rule when we tried to make pa have two containing spaces (the outer canvas and pab).
I'd like to note that we could not have expressed both subgraphs pab and pac using the approach that lacks indirection/whose syntactic structure is homomorphic to the graph layout. This is because the subgraph syntax is very clearly context-free: if we push each subgraph token and its scope onto a stack, each end token causes use to pop off that scope and match with the most recently pushed subgraph. We cannot get overlapping subgraphs with this syntax without references or some other indirection.
What to do?
During Kevin's co-op with me, he looked into several options for formatting the output graphs; none of the options we looked at supported overlapping subgraphs. This isn't surprising, but it doesn't absolve us of trying to represent the graphs to users. Our temporary solution was to simply label the nodes with the associated populations:
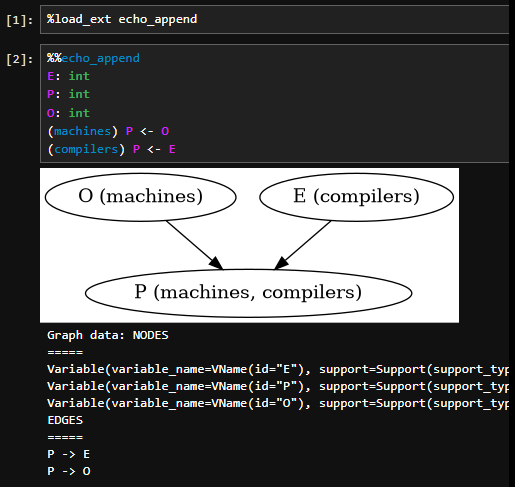
This is rather ugly and hard to read (both rather subjective and squishy statements, I know). It certainly seems like presenting subgraphs where we can makes sense. Therefore, as a first step, we want to classify whether we can express the specification and have a reasonably efficient translation from the internal representation to a graph specification language.
Abstracts and definitions
We can abstract over the two-variable example by using symbols represent {foo, bar} and {bar, baz}: respectively, and . The label on each subgraph corresponds to set expressions on and :
The sets denoted by each label together form a partion of populations:
As before, we can recover the set of populations associated with each variable by unioning the labels on the plates/containers/subgraphs:
If the above fails to convince, we can also write it out using set builder notation and reason over propositions instead:
Now let's consider what happens with three variables, , , and . Our partition becomes:
Let's map our three variable example to these quantities. Recall that = {foo, bar}, = {baz, bar}, = {foo, ham}. Then:
If we treat each set , , and purely syntactically (i.e., we forget that they represent sets and just treat them as literals), then syntactically, we are enumerating expressions for each subset of , i.e., over each element of .
You may notice that there's some punning on these syntactic expressions and subset relations: if is non-empty, it forms the outermost container; if any of are non-empty, then they will not contain any containers. However, the expressions themselves are not semantically subsets; this follows from the definition of a partition.
Classification
Recall that our main objective right now is to come up with a classification strategy for whether we can draw the graph. Our nice containment property is equivalent to testing whether the underlying structure forms a tree (or a forest).
Let's start by looking at the Hasse diagram for subsets of our three variable case:
Now let's overlay the syntax for each corresponding element of the partition:
...and now let's drop in some values for our examples. Since we care about a layout that also contains variables/nodes, we add these as leaves and remove the least element:
Practically speaking, if the top of the diagram — which maps to the outermost container — is empty, then that's one less constraint we have to worry about. We can safely remove that node from the graph without running into any issues. This leaves us with three new root nodes; we can repeat the process as we move from the top of the lattice, downward, stopping whenever we hit a non-empty node. This process results a new set of graphs:
Now we can clearly see that the first two examples depict graphs that represent the containment property, while the third violates our requirement that each node have exactly one parent (the layout issue that maps to an underlying tree structure).
Drawing trees and containers
Once we have determined that the popualation partitions form a tree structure, we can produce layout code algorithmically through breadth-first search.
For output that contains non-trees, the three main options I would consider are:
- Overlays, or
- Duplicated subgraphs, or
- Duplicated labels.
Overlays are the most sophisticated solution, requiring more complex Javascript and related tuning. I don't love this solution, since it's a lot work and I'm not sure it's worth the effort.
Duplicated sugraphs entails simply copying elements of the graph. This could be either nodes or population boxes. Implementation would be fairly straightforward, with a small amount of additional accounting (need to track aliases of the duplicated label).
Duplicated labels is the solution Kevin and I landed. I honestly don't hate this one, either, and it might be less confusing than duplicated subgraphs. However, the only way to really tell is with a user study, and we've run out of time and money on this project to actually answer that question!